데이터 입력(나영준, 송효진)
$ Rscript naverRelation.R 한국
을 통해 현 워킹디렉토리를 기준으로 검색키워드 "한국" 에 대하여
2차 연관검색어 정보가 네트워크 시각화 그림파일 한국.jpg 로 떨어지는 것을 구상중에 있음
추후 완벽하게 동작한다면 아래의 검색키워드 100개를 배치처리하여 100개의 네트워크 시각화 그림파일이 결과물로 반환되는 것을 목표로 함
샘플데이터 100
#
데이터크롤링(권용)
권용님께서 Giitbook 편집환경을 확인중입니다.
확인 후 반영될 예정입니다.
DB 저장(이은광)
RMD 파일 다운로드 받기 : https://github.com/eunkwang/DBInR/blob/master/aboutDB.Rmd
DB를 사용하는 이유
간단히 파일기반으로 데이터를 저장할 수 있으나 여러 시스템에서 데이터를 공유해야 할 경우 접근성이 떨어지고 여러 소스에서 데이터가 중복될 경우 관리하기 어려운 문제가 있어 DB 기반으로 시스템을 구축하는 것이 효과적임.
DB의 종류(https://inyl.github.io/programming/2017/05/09/database.html)
과거에는 RDBMS 기반의 시스템이 주류를 이루었으나 분산 처리 시스템이 발전하면서 NOSQL이 등장하였으며 현재는 목적에 따라 다양하게 골라서 이용할 수 있음. 스터디에서 공부하려는 DB는 파일 DB 형태의 sqlite3와 RDBMS 인 MSSQL 임.
파일DB
파일DB는 DB가 파일형태로 저장되지만 DBMS의 장점인 트랜젝션, 보안 등의 장점을 제공해주는 DB를 의미함. 대표적으로 sqlite가 있음
라이브러리 사용 하는 방법
# install.packages("DBI")
library(RSQLite)
datasetsDb()
# RSQLite Test
# 참고 자료 : https://cran.r-project.org/web/packages/RSQLite/vignettes/RSQLite.html
# DB생성
mydb <- dbConnect(SQLite(), "testDB.sqlite")
# DB 연결 해제
dbDisconnect(mydb)
unlink("my-db.sqlite")
# 메모리에 존재하는 임시 DB 생성
mydb <- dbConnect(SQLite(), "")
str(mydb)
dbDisconnect(mydb)
# DB에 데이터 프레임 기록하기
# DB에 저장되는 형태는 데이터 프레임과 유사
mydb <- dbConnect(RSQLite::SQLite(), "")
dbWriteTable(mydb, "mtcars", mtcars)
dbWriteTable(mydb, "iris", iris)
dbListTables(mydb)
# DB의 테이블 읽어오기
dbGetQuery(mydb, 'select * from mtcars limit5')
dbGetQuery(mydb, 'select * from iris where "Sepal.Length" < 4.6')
# 배치로 읽어오는 쿼리
rs <- dbSendQuery(mydb, 'SELECT * FROM mtcars')
while (!dbHasCompleted(rs)) {
df <- dbFetch(rs, n = 10)
print(nrow(df))
}
# 파라미터를 바꿔가며 처리하기
rs <- dbSendQuery(mydb, 'SELECT * FROM iris WHERE "Sepal.Length" < :x')
dbBind(rs, param = list(x = 4.5))
nrow(dbFetch(rs))
dbClearResult(rs)
# SQL 구문 실행하기
dbExecute(mydb, 'DELETE FROM iris WHERE "Sepal.Length" < 4')
rs <- dbSendStatement(mydb, 'DELETE FROM iris WHERE "Sepal.Length" < :x')
dbBind(rs, param = list(x = 4.5))
dbGetRowsAffected(rs)
dbClearResult(rs)
RDBMS
ODBC(Open DataBase Connectivity)
마이크로소프트가 만든 데이터베이스에 접근하기 위한 소프트웨어 표준규격으로 ODBC를 이용하면 각 연결된 데이터베이스가 무엇인지 상관 없이 동일한 방법으로 DB를 컨트롤 할 수 있음
JDBC(Java Database Connectivity)
자바에서 데이터베이스를 접속할 수 있도록 하는 자바 API이다. ODBC와 마찬가지로 JDBC를 이용하면 JDBC에 연결된 DB의 종류에 상관없이 동일한 방법으로 DB를 컨트롤 할 수 있음

ODBC 설정 방법(DB 사이드)
- DB 설치(이미 설치 되어 있다고 가정)
- ODBC Driver 셋팅(R이 설치된 PC)
- 윈도우 OS의 경우 드라이버가 기본적으로 설치되어 있음
- ODBC 설정 메뉴 진입
- 접근하고자 하는 DB 정보 설정
- R에서 DB 접근 하기
DB 설정 메뉴 진입하기

DB 설정하기

SQL 명령문
SQL의 명령문은 기본적으로 CREATE, READ, UPDATE, DELETE 로 이루어져 있으며 앞글자만 졸여서 CRUD로 표현한다. 가장 많이 사용하는 명령문은 READ 문이며 다음과 같은 문법을 따른다.
--CREATE
insert into [TARGET_TABLE] select * from [UPLOAD_TABLE]
--READ
select * from [TABLE]
--UPDATE
update [TABLE] set COLUMN = 1 where COLUMN = 2
--DELETE
delete from [TABLE] where COLUMN >= 3
R코드
R에서는 DB에 명령문을 실행하기 위해서는 커넥션을 오픈하고 명령문을 전달하고 커넥션을 닫는 형태로 명령을 수행함. DB로부터 데이터를 읽고 저장하고 수정하고 삭제하는 명령문은 함수 형태로 제공하고 있으며 sqlQuery 함수를 사용하여 SQL의 Query 구문을 그대로 실행할수 있음
# ODBC 라이브러리 로드
library(RODBC)
# DB 접속 계정 정보를 설정
con <- odbcConnect("DSN", uid = "userid", pw="password")
# DB의 TABLE 읽어오기
df <- sqlFetch(con, sqtable = "TABLENAME")
# R의 데이터프레임을 TABLE로 저장하기
sqlSave(con, df, tablename = "TABLENAME", append = FALSE)
# R의 데이터 프레임으로 TABLE 업데이트 하기
# 업데이트 하는 기준 컬럼을 지정해야 함
sqlUpdate(con, df, tablename = "TABLENAME", index = NULL)
# 테이블 삭제
sqlDrop(con, sqtable = "TABLENAME")
# 테이블 안에 모든 ROW 삭제
sqlClear(con, sqtable = "TABLENAME")
# sqlQuery 명령어를 사용하면 보다 R안에서 SQL 구문을 보다 범용적으로 사용할 수 있음
query <- paste0( "SELECT TOP 1000 [Country]
,[keywordType]
,[subKeywordType]
,[keyword]
FROM [Temp].[dbo].[keywordDic]")
dataset <- sqlQuery(con, query)
참고자료
데이터전처리(김선화)
1. Tidy 텍스트 포맷
* token : 분석에 사용하려는 단어처럼 의미있는 텍스트 단위
* 토큰화
텍스트를 토큰으로 분할하는 과정
분할 단위 : 단어, n-gram, 문장, 줄, 문단, 정규식 패턴
* 텍스트 마이닝에서 각 행에 저장되는 토큰은 대개 한 단어이지만 문장 또는 단락일 수도 있음
* String : 텍스트는 문자 벡터로 저장 가능
* 코퍼스(Corpus) : 위 유형의 객체는 일반적으로 추가 메타 데이터 및 세부 정보로 주석된 원시 문자열(raw string)을 포함
* Document-term matrix
"행 : 각 문서 / 열 : 각 용어"의 형태를 갖는 문서의 모음(즉, 코퍼스)을 설명하는 sparse한 행렬
행렬의 값은 일반적으로 단어 수 또는 tf-idf
* stop words : 텍스트 분석에서 종종 분석에 유용하지 않은 단어, 일반적으로 영어의 "the", "of", "to" 등과 같은 매우 일반적인 단어
2. 감성분석
* 텍스트 감성를 분석하는 방법은 텍스트를 개별 단어의 조합으로 간주하고 전체 텍스트의 감성 내용을 개별 단어의 감성 내용의 합계로 간주 (자주 사용되는 접근 방식)
* 의견, 감정을 텍스트로 평가하기 위해 다양한 방법과 어휘집 존재
* tidytext 패키지에 감성 어휘집이 있고, 어휘집 종류로 NRC, Bing, AFINN이 있음
* 각 단어에 긍정/부정적 감정을 위한 점수와 기쁨, 분노, 슬픔과 같은 감정이 할당됨
* NRC 어휘집은 "예"/ "아니오"로 단어를 긍정, 부정, 분노, 기대감, 혐오감, 두려움, 기쁨, 슬픔, 놀라움 및 신뢰의 범주로 분류
* Bing 어휘집
"예"/ "아니오"로 단어를 긍정, 부정 범주로 분류
각 소설에서 감정이 어떻게 변하는지 조사할 수 있음
inner_join()을 사용해 각 단어에 대한 감정 점수 찾기긍정/부정적인 단어 수 세기
* AFINN 어휘집
-5에서 5 사이의 점수를 갖는 단어를 할당
-는 부정적인 감정, +는 긍정적인 감정
* 많은 영단어가 꽤 중립적이기 때문에 모든 영어 단어가 어휘집에 있는 것은 아님
* "좋지 않다" 또는 "사실이 아님"처럼 단어 앞에 한정어를 고려하지 않음
* 감정 점수를 더하기 위해 사용하는 텍스트 청크의 크기가 분석에 영향을 줄 수 있음
많은 단락의 크기를 갖는 텍스트는 종종 긍정적이거나 부정적인 감정을 평균을 약 0으로 내며
반면 문장 크기 또는 단락 크기의 텍스트는 더 잘 작동
i. 감성 사전 비교
* AFINN 어휘집 이용 시 상대적으로 높은 절대값과 높은 양수를 보임
* Bing 어휘집 이용 시 절대값이 낮고 인접한 양수 또는 음수 텍스트의 큰 블록을 표시하는 것으로 보입니다
* NRC 어휘집 이용 시 상대적으로 더 높게 이동하여 텍스트를 보다 긍정적으로 표시하지만 텍스트의 비슷한 상대적인 변화를 감지
* NRC 감정이 높고, AFINN 감정의 편차가 더 크며, Bing 감정은 유사한 텍스트가 더 길게 늘어나는 것처럼 보입니다. 그러나 이 세 가지 모두는 서사를 통해 감정의 전반적인 추세에 대략 동의
* Bing 어휘집에서 NRC 어휘집보다 부정/긍정어의 비율이 더 높기 때문에 NRC 어휘집이 감정에 편향된 것처럼 보임
* 어떠한 어휘집을 이용하든 전반적인 경향은 비슷하지만, 세부적인 점은 다르기 때문에 어휘집 선택 시 주의
ii. Wordclouds
* Wordclouds를 이용해 가장 중요한 긍정 및 부정적인 단어를 볼 수 있지만 단어의 크기는 감정을 뛰어 넘어 비교 불가
iii. 개별 단어 그 이상
* 개별 단어의 긍정/부정 이해가 아닌 문맥상 감정을 고려해야 할 상황이 있음 ex) 나는 좋은 날을 보내지 못한다 > 기존 알고리즘으로는 긍정적인 문장으로 받아들임
* 이러한 문제는 개별 단어가 아닌 문장 단위로 토큰화하여 해결할 수 있음
단, 문장 토큰화는 UTF-8로 인코딩된 텍스트, 특히 대화체 섹션에 약간 문제 있음
구두점을 ASCII로 사용하면 훨씬 효과적
* 정규식 패턴 단위로도 토큰화 가능
3. 단어 및 문서 빈도 수 분석(tf-idf)
* 많이 등장하는 단어의 가중치는 줄이고 흔치 않은 단어의 가중치는 높이는 방식
* idf(term) = ln (ndocuments / ndocuments containing term)
i. Zipf’s Law
* 단어의 빈도 순위들과 대응되는 term frequency는 감소하는 반비례 관계
$$ frequency \propto \frac{1}{rank}
$$
ii. The bind_tf_idf Function
iii. A Corpus of Physics Texts
4. 단어간 관계: N-grams and Correlations
* 지금까지는 단어를 개별 단위로 간주하고 감정이나 문서에 대한 관계를 고려
* 많은 흥미로운 텍스트 분석은 단어 간의 관계에 기반함. 즉, 어떤 단어가 다른 단어를 즉시 따르는 경향이 있는지 또는 동일한 문서 내에서 연달아 발생하는 단어인지를 분석
i. N-gram으로 토큰화
* unnest_tokens(token = "ngrams", n = 지정)를 사용해 n-gram이라고 하는 연속적인 단어 n개로 토큰화할 수도 있음
- n = 2 : 연속적인 단어 2개씩 확인 (이 경우 특별히 bigrams라 함)
* 단어 X가 단어 Y를 얼마나 자주 따르는지 봄으로써 그들 사이의 관계에 대한 모델을 만들 수 있음
ii. paired된 단어 카운팅 및 상관관계 확인
* widyr Package 이용하여 tidy text를 행렬로 변환 후 분석
a. 섹션간 카운팅 및 상관 관계 확인
* "한 섹션 = 10줄"이라고 지정할 수 있음 (사용자 임의로 지정)
* 같은 섹션 안에서 어떤 단어가 나타나는 경향이 있는지 확인할 수 있음
* pairwise_count 함수 이용
* 단어 간의 상관 관계는 단어가 얼마나 자주 나타나는지, 자주 표시되는지는 phi 상관계수라는 것으로 알 수 있음
* pairwise_cor 함수 이용
* phi 상관계수를 기준으로 pairwise_cor 함수를 이용하여 단어들을 클러스터링할 수 있음
#
시각화(이기섭)
개요
R을 이용하여 대표적인 검색사이트인 네이버에서 입력한 키워드에 대한 연관검색어들을 crawling하고, 그 자료들을 보기 쉽게 시각화 하는 것을 목표로 한다. 앞선 단예에서 자료의 오염이나 기타 수집단계에서의 전처리가 완료되었다 하더라도 시각화에 사용하는 함수에 적합한 형태로 구조적 전처리를 병행해야 한다. 따라서 시각화 함수 내에서 필요한 자료 가공을 수행한 뒤 미려한 그래프를 그리는 것이 목적이다.방법
i. Word Cloud
ii. Word NetworknaverRelation()함수로 수집된 자료 또는loadHistory()함수를 이용하여 DB에서 불러온 자료(이하 입력자료)는plot.nr()함수의 내부에서 network plot을 그리기 적합한 형태로 전처리된다.naverRelation()함수에서는 불러올 연관검색어의 depth 인자를 사용하고 있기 때문에 시각화 함수에서는 다음과 같이 depth 속성을 인지하여 반응하도록 설계하였다.if(attributes(x)$depth == 1){depth=1 일때 동작함수`} else if(attributes(x)$depth == 2){depth=2 일때 동작함수입력자료는 keyword인 "R0", 1차 연관검색어인 "R1", 2차 연관검색어인 "R2"로 table화 되어 있다. 이 자료는 아래 a~e의 과정을 통해
networkD3::forceNetwork()함수의 인자로 사용 가능한 형태로 변환한다.a. depth=1 일 때에는 "R0"와 "R1" 열을
dplyr::count()함수를 이용하여 각 검색어들을 다음 그림과 같이 빈도수로 계량화 하고,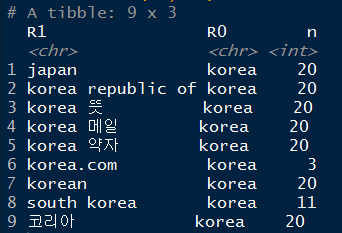
depth=2 일 때에는
x[c("R0", "R1")]data set과x[c("R1", "R2")]data set을rbind()함수로 쌓아올린 뒤dplyr::count()함수를 사용한다. 다음과 같이 쌓아 올린다.x1 <- x[,1:2]; colnames(x1) <- c("R1", "R2")x2 <- x[,2:3]; colnames(x2) <- c("R1", "R2")new_x <- rbind(x1, x2)b. a의 결과물을 igraph::graph_from_data_frame() 함수로 각 검색어들의 연결관계를 구조화시킨 형태로 변환한다. 변환된 형태는 다음과 같다.
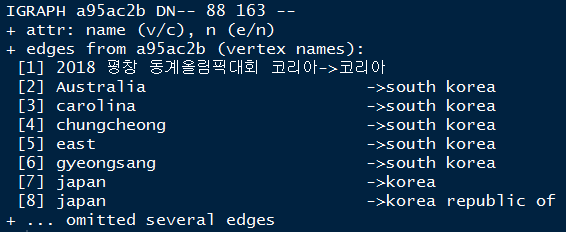
자료는 단어에서 단어로의 연결관계를 나타내며
igraphclass로 정의된다.c.
igraphclass로 변환된 b의 결과물을networkD3package에서 표현 가능한 형태로 변환시켜주는networkD3::igraph_to_networkD3()함수를 이용하여 처리한다. 처리된 자료는 아래 그림과 같이 links와 nodes 이름을 갖는 list형태로 반환된다.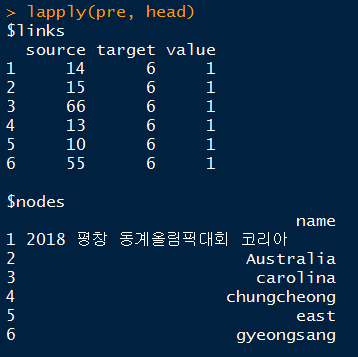
d. c에서 list 형으로 반환된 자료 중 nodes 항목에는
networkD3::forceNetwork()함수에서 요구하는 group 정보가 빠져있다. 따라서 R0는 "keyword", R1은 "1st Relation", R2는 "2nd Relation"으로 group을 부여한다. 코드는 다음과 같다.pre$nodes$group <- ifelse(pre$nodes$name %in% x$R0, "Keyword", ifelse(pre$nodes$name %in% x$R1, "1st Relation", "2nd Relation"))e. d의 결과물을
networkD3::forceNetwork()함수에 적용시킨다. 시각화 옵션은 아래 코드와 같이 적용했다.networkD3::forceNetwork(Links = pre$links, Nodes = pre$nodes, colourScale = JS("d3.scaleOrdinal(d3.schemeCategory10);"), Source = "source", Target = "target", Value = "value", NodeID = "name", Group = "group", opacity = 0.9, zoom = T, fontSize = 20, fontFamily = "serif", legend = T, opacityNoHover = 0.1)결과
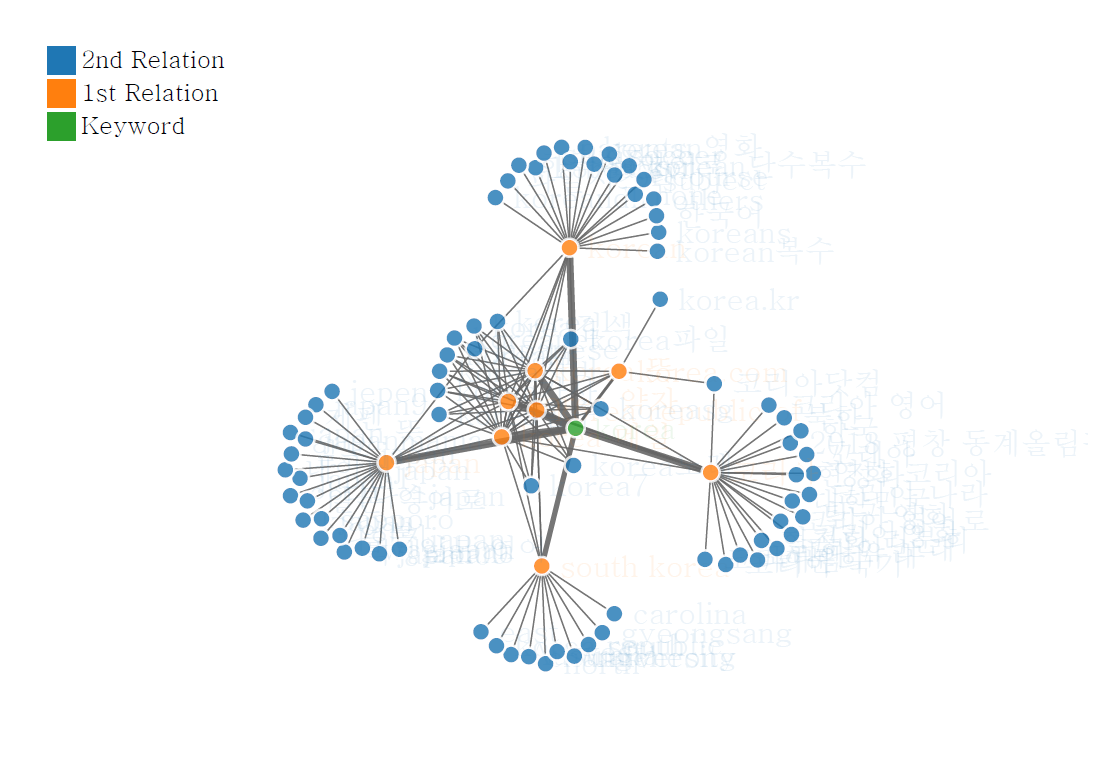
참고자료
Csardi G, Nepusz T. (2006). The igraph software package for complex network
research, InterJournal, Complex Systems 1695. http://igraph.org.Hadley Wickham (2007). Reshaping Data with the reshape Package. Journal of Statistical Software, 21(12), 1-20. URL http://www.jstatsoft.org/v21/i12/.
Hadley Wickham. (2016). rvest: Easily Harvest (Scrape) Web Pages. R package version 0.3.2. https://CRAN.R-roject.org/package=rvest.
Hadley Wickham. (2018). stringr: Simple, Consistent Wrappers for Common String Operations. R package version 1.3.0. https://CRAN.R-project.org/package=stringr.
Hadley Wickham, Romain Francois, Lionel Henry and Kirill Muller. (2017). dplyr: A Grammar of Data Manipulation. R package version 0.7.4. https://CRAN.R-project.org/package=dplyr.
J.J. Allaire, Christopher Gandrud, Kenton Russell and CJ Yetman. (2017). networkD3: D3 JavaScript Network Graphs from R. R package version 0.4. https://CRAN.R-project.org/package=networkD3.
Kirill Muller, Hadley Wickham, David A. James and Seth Falcon. (2017). RSQLite: 'SQLite' Interface for R. R package version 2.0. https://CRAN.R-project.org/package=RSQLite.
Klaus K. Holst and Esben Budtz-Joergensen. (2013). Linear Latent Variable Models: The lava-package. Computational Statistics 28 (4), pp. 1385-1452. http://dx.doi.org/10.1007/s00180-012-0344-y.
Silge, J., & Robinson, D. (2017). Text mining with R: A tidy approach. O'Reilly Media, Inc.. pp. 179.
Stefan Milton Bache and Hadley Wickham. (2014). magrittr: A Forward-Pipe Operator for R. R package version 1.5.
https://CRAN.R-project.org/package=magrittr.
슬랙으로 결과 서빙(Slash Command)
- 배경과 목표
- 슬랙을 통해 동작하는 프로그램을 만들어 서비스로 연결함
- 세부내용